
Orange Fairness Add-On
Checking AI for discrimination via GUI using the Orange Fairness Add-On
The open source software Orange Data Mining makes it possible to create data science workflows and artificial intelligence with drag-and-drop elements. For workshops, research and applications in companies, the tool is particularly suitable for learning AI, communicating, making projects understandable and achieving rapid success. With the Fairness add-on, you can now also make machine learning models with Orange fairer.
Fairness & artificial intelligence? A digression
As we allow artificial intelligence and machine learning models to make more and more decisions for us, it is becoming increasingly important to ensure that the models also make decisions that are in line with our values, laws and corporate culture. This applies in particular to AI that makes decisions that influence people, e.g. in lending, pricing or communication. In the field of data science and machine learning, the focus has long been on optimising the accuracy and predictive power of models. In recent years, numerous negative examples in the media have made it increasingly clear that, in addition to predictive power, aspects such as fairness, interpretability and data protection also play an important role in the development and application of artificial intelligence. Research in this area is done, for example, at the interdisciplinary research centre TOPML at Mainz University, funded by the Carl Zeiss Foundation. Tried and tested methods have emerged from academic research that help to understand black box models or to design fair AI models.
In 2023, the University of Ljubljana published a fairness extension for Orange. This package can be easily installed via the python packaging index (pip) or downloaded via a link. With the free extension to the free tool, data sets and machine learning models can be quickly checked for bias and discrimination and improved using advanced methods. A good opportunity to provide a brief overview of fairness metrics, methods and implementation in Orange.
Dataset bias – the source of many data science ills
Since every statistical model and every machine learning algorithm learns from data and ultimately generalises correlations, the database is essential for developing strong AI. Inaccurately measured or entered data is a horror for data science and artificial intelligence: it distorts insights and models and makes it difficult to find a suitable function between input data and output label. In addition to traditional methods such as outlier analyses, plausibility checks or multicollinearity checks, there are also metrics that determine the fairness of a data set. But how can a data set be (un)fair at all?
First of all, a data set is created more or less objectively. Measurement errors and incomplete data are the main reasons for this. The normative dimension comes into play above all as soon as personal data is involved. This is because AI models generally reproduce discrimination that may be contained in the data. When it comes to criminal offences, for example, it is possible that crimes committed by people with a migration background have a higher clearance rate due to focused police work. Offences committed by white people would then be underreported. This can lead to distorted model outputs. If, for example, a company determines the risk of fraud on the basis of data and rejects an order (such as a parcel delivery), it is possible that more migrants will be denied the service. However, unequal treatment based on sensitive attributes such as origin or gender is illegal under the AGG. In addition to legal consequences, this can also result in reputational damage. Fairness therefore plays an important role in the field of data science and machine learning if there is a favoured outcome (e.g. granting a loan, job interview) that depends on attributes such as gender, origin, sexual or religious orientation. With the ‘As Fairness Data’ widget, data records in orange can be noted in such a way that fairness metrics and fair models can then be calculated. To do this, the favoured outcome, the sensitive attribute and the privileged group must be marked.
Fairness metrics – so that AI learns fairly
With the DataSet Bias widget, fairness metrics can already be calculated on the data set. The Disparate Impact and Statistical Parity Difference metrics quantify the extent to which the groups differ with regard to the desired outcome. If the disparate impact is 1, this would mean, for example, that women and men in the data set have the same probability of receiving a favoured outcome, e.g. if 30% of women and 30% of men were approved for a requested loan. Such a data set would therefore initially be unproblematic. If 70% of men were approved for a loan in the past and only 20% of women, the disparate impact would be well below 1. A statistical model would reproduce this inequality. The obvious solution would be to remove the sensitive attribute such as gender from the data set. Unfortunately, this only helps to a very limited extent, as complex ML models can implicitly infer gender or origin via correlated attributes (e.g. order history, name, etc.). Even after removing the gender attribute, an artificial intelligence will then preferentially approve a loan for men. To prevent this, there are various methods for training fair models. The data can be specifically processed before learning the machine learning model (pre-processing), the optimisation function of an algorithm can be expanded (in-processing) or the model results can be adjusted afterwards (post-processing).
Reweighing – machine learning with weights
The Reweighing pre-processing method can be easily integrated into the DataScience workflow as a practical Orange widget. The reweighing algorithm adds a new column with weights to the data set. These weights can then be used in modelling to learn more or less from certain cases. What exactly is behind the algorithm is too much to go into here. It is important to note that not all machine learning algorithms can learn with weights. This can be avoided by sampling the data set with the weights as probabilities so that all model families can benefit from reweighing.
Adversarial debiasing – limiting AI knowledge, unlearning discrimination
This orange widget and the underlying algorithm [1] are an in-processing method. The optimisation function of a model is extended by one term. In addition to a classic error metric such as the mean squared error, such a fair model should also unlearn the relationship between the sensitive attribute and the outcome. This makes the model as independent as possible of problematic attributes such as gender or origin. Compared to other fairness methods, in-processing methods tend to achieve a particularly high model quality.
[1] Zhang et al., 2018, DOI 10.1145/3278721.3278779
Equal odds post-processing – improving machine learning after training
This orange widget uses the AIF360 Python library to adjust the results of a model. The inequality between the false-positive and false-negative rates of the sensitive groups is deliberately minimised. Because fairness goes beyond equality. Much more relevant than equal outcomes (e.g. 30% creditworthiness for men, 30% creditworthiness for women) is the balance of errors in a model. An AI is particularly unfair if sensitive groups are wrongly assigned a negatively connoted output.
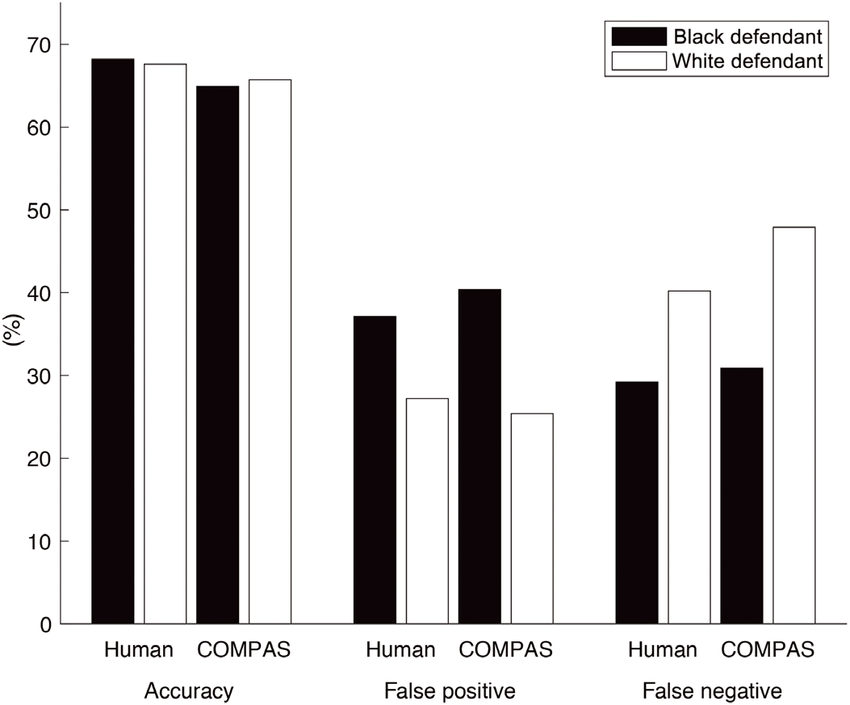
The famous COMPAS case illustrates the problem perfectly: the judge-assisting AI system used in Florida assessed the recidivism probability of people of colour to be significantly higher within two years than was actually the case. The model systematically underestimated the reoffending of white people. The false-positive rates were therefore unequal.
Conclusion – learning to make AI fair & interpretable
AI models are being used more and more frequently to make relevant decisions, which is why it is becoming increasingly important to ensure their fairness. Pre-, in- and post-processing methods can create security and help to ensure that the use of artificial intelligence is legally unproblematic and that no reputational damage occurs. The Orange add-on makes it particularly easy to integrate fairness into the data science workflow. Data and models can be checked for discrimination and customised.